最近时间比较充裕,作为一个用户对Cassandra的认识也算逐渐深入,因此开始系统性地来阅读源码。看明白某个地方之后就随手写个博客啥的,帮自己整理思路,顺便争取让看到的人有所收获。
之前提到过俺们公司放弃了自己造的分布式数据库轮子,开始用Cassandra,几个月以来虽然有各种小坑,但大坑暂时没遇到。而且小坑有超过一半是因为我们是从现有机器里找了一批即将下线的性能最挫的没人要的机器来搭,磁盘也不够大,导致load太高、磁盘性能变差或者磁盘满了从而影响线上服务。目前词典的单词真人发音或例句tts发音、单词本,还有有道公用的图片服务的底层数据都在Cassandra上,总体说来还是挺靠谱的。互联网相关的技术发展速度太猛,一两年一个大变样,不比摩尔定律慢,Cassandra初期不靠谱然后导致2010年左右连FB自己都放弃了之后留下太多黑它的言论,于是导致在2013、2014年很多人提到Cassandra还是看到了历史时期尤其是1.0之前时期的吐槽最终放弃调研Cassandra,还是挺遗憾的。尤其是其实2013年开始FB自己也重新在某些项目用Cassandra了,不过谁让Cassandra的资料比hbase少太多呢,尤其是连官方wiki都弱爆了,完全是靠Datastax那个商业公司写版权属于他们公司的文档。当然那个文档只能作为用户看,大多数时候没太说底层的实现,好奇心太重的话,还是要看代码。
言归正传,C*(按社区惯例,Cassandra简写为C*)因为去掉了中心节点master,也不用分布式的管理组件zookeeper,完全是靠W+R>N来实现数据读写的一致性,能保证读到的一定是“时间戳最大”一次写过的。但如果俩线程同时写,会导致一前一后写进去,两个client线程都认为自己写成功了,但实际上后写的覆盖了新写的,也就是ACID里的I,隔离性,没保障。举例就是,俩用户同时抢注一个id,业务逻辑会因为都写成功了而认为俩人都注册成功了,但实际上是冲突了。
所以C*从2.0开始基于Paxos算法支持轻量级单row key事务,来确保隔离性。支持的操作主要是insert … if not exist; delete … if exist; update … if col=value三种,另外不常用的可能就是create table if not exist和drop table if exist。其一致性也不再是对数量的要求而是linearizable或者本地机房内linearizable即local_linearizable。当然,基于insert if not exist以及ttl完全可以实现一个简易的分布式锁,执行更复杂的逻辑。拿到插入权就是拿到了锁,拿不到就短暂sleep后再尝试。ttl是为了让这行数据在一段时间后自动删除,防止拿到锁之后程序挂掉没删除导致死锁。
介绍具体实现前先简单介绍下C*的架构。它是典型的SEDA(Staged Event-Driven Architecture)架构,即把一个完整行为拆分成若干个阶段(Stage),阶段之间用消息和回调进行异步交互。因为一个完整的操作流程在不同阶段对资源的占用是不同的,这个架构可以比较方便的在不同阶段开不同大小的线程池从而最大化全局的性能,同时因为有一个消息传递的中转队列,一定程度上也算解耦合,只需要根据中转队列的接口实现一个个阶段的handler即可。C*里有个专门的MessagingService负责收发消息,每个消息有个对应的Verb枚举类来说明这个消息是什么类型的,用一个map来注册收到某个消息后该被哪个Handler接收。发消息可能发给本地也可能发给其他节点。
跳过从某个节点接到client请求到处理完CQL语句等部分,当发现query中包括了”if”这种有条件的行为即轻量级事务之后,执行StorageProxy.cas方法。StorageProxy可以理解为对任何查询的处理,再此之前的东西(主要是处理CQL或者旧版的thrift请求)好像都不是异步的。cas方法中先通过row key获取token,根据token算哪几个节点存了这份数据。然后开始进行Paxos算法的prepare阶段——这个阶段和C*自己的SEDA的阶段两码事。
将Prepare消息发到所有保存该row key的节点,对应节点的MessagingService收到了MessagingService.Verb.PAXOS_PREPARE这个类型的消息后由对应注册的PrepareVerbHandler来处理。Paxos的prepare阶段很简单,收到prepare的消息后跟本地已经收到的最大版本号(C*里用timeUUID来作为版本号)比较,比之前的大则接受,否则拒绝并让发起者终止本次请求。
具体实现是在PaxosState.prepare方法,因为prepare的状态更新要保证线程安全,里面搞了1024个锁,先把key哈希在0-1023之间然后用synchronized同步。进了同步块之后,先从system.paxos表拿query对应表对应行的状态。system这个keyspace是专门存各种系统信息的,读写应该都不会和其他节点进行同步,各搞各的(于是如果data存在多个磁盘然后其中一个磁盘挂了就可能会导致system数据损坏然后开始各种莫名其妙,所以我现在如果换一个盘也都会把那个节点数据全清空重新nodetool rebuild从其他节点导数据)。paxos这个表的定义如下:
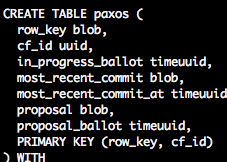
in_progress_ballot、proposal、most_recent_commit分别代表正在提议(prepare)、已经接受提议(propose)和最近一次提交成功。注意这个接受是按照paxos算法需要多数同意且无人否决(同意和否决之外的第三种情况是超时无响应)这个提议之后才算“接受”,自己“同意”某个提议不算。拿到这个信息之后,用in_progress_ballot跟收到的这个消息的时间戳做比较,如果相同或收到的更大(判断是否相同好像是因为可能会重试?不然timeuuid理论上应该不会重复的啊而prepare也不会用同一个版本号重复两次,难道我理解错了……)就同意这个提议。如果同意就把这个时间戳更新到system.paxos表对应行的in_progress_ballot中,并设ttl。判断能否同意这个提议之后,返回个bool类型回调给发起提议的leader(即收到client请求的那个节点)。如果为true则额外返回最近一次接受的内容以及最近一次提交成功的内容,内容包括具体query和版本号,即proposal、proposal_ballot和most_recent_commit、most_recent_commit_at;如果为false额外返回已经收到过的那个prepare的版本号以及最近一次提交成功的内容即in_progress_ballot和most_recent_commit、most_recent_commit_at。回调也是一次消息传递,由N个节点发送给处理client请求的那个节点。
PrepareCallback负责处理回调,一次prepare请求只有一个callback实例,多个节点分别回调都会调用这一个实例。处理callback的时候同时记录所有返回的节点的inProgressCommitWithUpdate(in_progress_ballot/proposal)最大版本号以及commit成功的最大版本号,这两个版本号后面会用。在超时时间结束前如果有多数节点同意且无人拒绝则通过此prepare;只要有一个节点拒绝提议,整个提议作废中止;超时时间截止前没有多数同意,直接抛超时异常,似乎就不会再重试直接报错给客户端。
如果被拒绝,把导致中止的回调传来的in_progress_ballot+1和当前系统时间戳取最大生成一个新的版本号再尝试prepare,之所以要两者最大是因为每个节点的时钟可能有偏差,要保证全局总是更大的。处理每个回调的请求的同时,分别保存所有回调中proposal_ballot和most_recent_commit_at的两个最大值(就是上一段提到的两个版本号)。如果发现有前者比后者大,说明目前系统的状态(数据)并不是最新,即使对应节点接受了本次prepare也需要先完成前一次commit。所以会先用自己生成的这个版本号推进他完成(用这个版本号执行后续propose、commit阶段)。这样才能保证总是先prepare的请求先commit,并且每次commit前看到的数据都是之前所有prepare都commit完的状态,从而保证整体的修改都是linearizable。把没commit的旧请求commit了之后,再重新生成个更高的版本号重新prepare。
prepare真的没任何问题之后,相当于锁住了该行数据修改序列的一个位置,后续修改一定会基于这次修改(如前面所说,会等前面的修改彻底执行完毕甚至自己推进这次修改),这次修改也会基于之前的修改因为如果没修改成prepare是不会结束的。所以这时候读到的数据是被锁住的数据,可以拿来判断事务条件。因此执行QUORUM的读把该行数据最新的值读出来,与query语句中if的条件进行比较,如果不满足条件直接退出整个cas流程,否则开始准备写入数据。写入之前会写执行trigger(如果存在的话),对C*的trigger还不太了解,先跳过……
接下来的propose阶段实际上和prepare几乎一样,目的是通知对应的节点刚才那次prepare在整个集群上似乎也许大概可能都是没有问题的,接下来你们要知道这次改动的具体内容,并保证任何更新的commit之前这次改动都得先commit。发PAXOS_PROPOSE类型的消息到对应的节点,其版本号沿用之前成功的prepare的版本号。收到消息的节点从本地system.paxos表里读数据比较已存的promised版本号和这次propose的版本号,如果propose>=promised则通过否则拒绝(prepare阶段一个节点接受prepare之后就会拒绝一切比这个版本号旧的内容)。如果通过就update本地的system.paxos表的proposal_ballot字段,同时保存下update的具体query,一样有ttl。回调数据比较简单,只有一个bool。
propose的结果返回之后直接就只是看是否多数人接受,如果是则直接可以commit,否则需要重新执行整个cas逻辑,重新prepare。
如果可以commit,就继续挨个节点发PAXOS_COMMIT类型的消息,收到消息的节点在本地修改对应的数据然后在system.paxos表更新对应的信息(保存most_recent_commit,清空in_progress_ballot/proposal),将处理成功的消息回调给leader节点,超过半数节点返回成功后,leader节点给客户端返回query执行成功的消息,整个cas修改操作执行完毕。
因此整个C*实现轻量级事务的流程图是这样的:
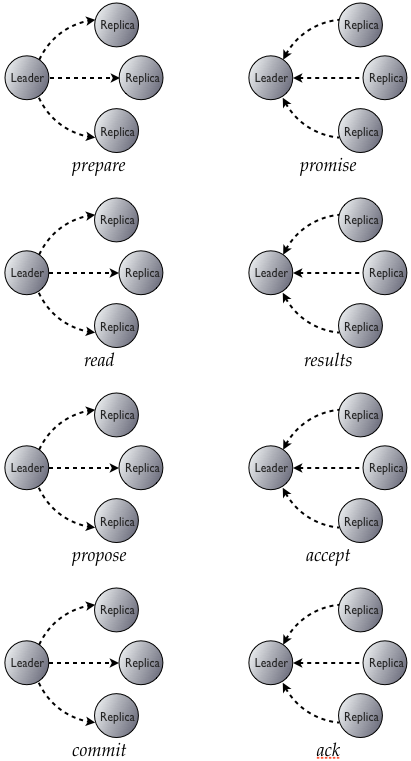
可以看到因为逻辑尤其是通信和本地读写请求次数数倍于普通的读写,所以性能会比普通的写操作慢很多。因此除非确实有必要否则直接用普通的写就好,当然其实C*的性能挺强的,带事务的感觉可能也没慢到不能忍,尤其是马上发布的2.1好像比2.0又提升了不少读写性能。
之所以看cas而非标准的读写主要是感觉cas的逻辑会复杂些。弄懂这个应该弄懂普通的读写就很容易了。当然这里略微跳过了一些特殊情况的处理,主要是有节点刚加入正在导数据,以及防止因为节点挂掉丢数据而做的一些repair操作。
发表回复