虽然上一篇文章写于Pony股价4.3刀的时候,如今已经很多倍了,很多人看了我的文章后更坚定地买入和持有然后赚了好多快钱。但本文还是不作为投资建议,Do Your Own Research。
(一)锤子和钉子
技术创业,或者说通过科技创新赚取利润的行业,有些行业是锤子找钉子,有些行业是钉子找锤子。
锤子找钉子的行业,各家公司实现了某种技术,这个技术能做到某个能力,但这个能力无法直接变现,需要包装成实际用户(无论toB还是toC)所能用的功能,和产品,然后才能变现,甚至可能无法变现。无法变现的钉子,要么是伪需求,要么是目标用户太穷,要么是做锤子的门槛没有那么高,相比于需求,会供给过剩。
钉子找锤子的行业,钉子就在那,需求就在那,钱也在那,但是技术上很难,谁做出来,谁能把钉子锤进去,谁就一定赚钱。无法变现的锤子,只有一种可能——技术菜、根本不满足用户真正的需求。
第一代AI公司做的人脸识别就是锤子找钉子的赛道,四小龙都有人脸识别的算法能力作为锤子,找了很多年钉子,最后都在卖安防硬件卷价格。而L4级自动驾驶,尤其是Robotaxi,就是反过来钉子找锤子的行业。产品形态不需要太想,谁能把技术做好,价格做低,体验做好,谁就能赚钱。机器人,如果把目标设成AGI下的通用机器人,也肯定是如此,只是还太久远,现在只能是遥控打拳击。大语言模型LLM实现的ChatBox,也是类似。需求一直在,甚至类似的产品早就有,既可以做助手,也可以做聊天陪伴,但直到ChatGPT甚至GPT3.5之后,才真正满足用户的大多数需求,从而迎来行业的爆发。
上述这些钉子找锤子的行业,都不需要想太多商业模式、产品形态的创新,只需要技术上做到合乎要求的水平即可,这很像是“做题”,有明确的考纲(目标明确),比谁分高(只需要努力达到目标)而不是比谁更有新奇的想法。
(二)考试和评分
但看似简单的目标,必然有很难的问题需要解决,否则就变成了技术过剩,成了内卷的赛道。或者说,Robotaxi和大语言模型,都是“区分度非常高”的考试,而不是“大家都几乎满分,比谁细心”的考试——更像是高中生的“国际奥赛”,而不是中考。
当然,因为人类的知识也在进步,年轻人的考试能力也会越来越强,几十年前的国际奥赛题,可能几十年后变成了高考级别的题,但一定不会变成中考题——有些是会跟着人类社会进步,但有些还是要考虑到客观物质极限。30-50年后的年轻人,会不会随便就靠AI手搓出来一个自动驾驶算法,或者大语言模型,谁也不知道,但起码10-20年内,不至于。
大语言模型的考题是什么、评价大语言模型好坏的标准是什么?有些人虽然还是不清楚,但整体上很多稍微聪明点的人是能大概判断出好坏的。比如,大家知道问AI得到的答案是好是坏,好的就是好模型。不会去列到底某个AI产品都有哪些功能,有8个功能的就比5个功能的好。至于哪个答案更好,其实是稍微难判断的,除非有显著的差异,而目前头部的模型,其实很难说答案会有显著差异了。于是大家开始靠刷榜看评测集分数去评价,既有他的科学性,也有他的问题,这里先不展开。
那Robotaxi、自动驾驶的考题是什么,如何评价自动驾驶的好坏?其实这个问题本身,也是个考题,很多人其实根本不清楚。比如拿L2辅助驾驶来说,消费者甚至车企的从业者,两三年前可能还停留在“有8个功能的就比5个功能的好”和“都有这个功能就是一样好”的阶段。直到现在各家都有了8个功能,尤其是“点对点NOA”真的成为了功能,并且头部NOA比腰部尾部NOA的体验差了十万八千里,公众似乎终于知道要评价自动驾驶能力,而不是功能数量了。
(三)一起来学统计学
那自动驾驶能力怎么评价?很多人会知道MPI,也就是接管率,这是个统计学问题,但是这个社会大多数人的统计学是不及格的,喜欢“身边统计学”,也不知道什么叫“控制变量法”。比如,加州DMV从将近十年前开始就会公布各家公司在加州路测的MPI,至今很多人会觉得那个榜单MPI高的就是牛逼的——而这就是不懂什么叫“控制变量”(大家路测的时间、地点和场景难度完全不一样),也可能在搞“身边统计学”(总里程1万和总里程100万的数据意义完全不一样)。几年前,某车企找到了某供应商,这个供应商号称自己除了L2也能做L4,就答应帮车企搞Robotaxi,承诺MPI可以100甚至更高(当然这不代表可以L4,咱暂且不论),最终,是靠在大半夜没有人的时候跑没有人的路,完成了这个目标,甲方乙方都很高兴。
在统计学上,小样本无法测出低概率事件的准确概率,这就是所谓不能“身边统计学”。坐一次滴滴没有遇到事故,不代表一辈子都不会遇到事故;同样,坐一小时L2 NOA没有事故/接管,不代表一辈子都不会遇到事故。但坐滴滴的事故率,和L2 NOA的事故率,和坐能无人的真L4 Robotaxi的事故率,可能是三个不同的数量级。换个通俗的说法,就是你一边睡觉一边用辅助驾驶,用100次可能99次是到了导航的终点,1次是到人生的终点。
而同样是Robotaxi,敢给你体验个有安全员的demo,和敢给你体验个无安全员的demo,和敢让你公开打到10台无安全员的车,和敢让你公开打到100台无安全员车,其背后的难度是分别差一个数量级的。同样是100台车,甚至几百台车,敢让你在高峰期、繁忙地段打车,和只敢在非繁忙地段和时段让你打车,其背后的难度也是分别差一个数量级的——因为复杂场景的事故率远高于非复杂场景,哪怕人类都是如此。
“敢”做这些事情,除了完全不要命拼一把(可能不拼就融不到资了)的外,理性人是会根据自己实际知道的事故概率去来决定给你体验什么东西的。等到了“上百台无人车随便让你打”这个阶段,每天无人车在外面跑的总里程就已经是几万公里这个量级,而人类司机的事故率(不考虑是否有责任)就已经是在这个量级、几万公里碰一次,所以从统计学的角度,如果一家自动驾驶公司的安全性跟人类相近,其实100台无人车就是平均每天出一次事故。但显然公众不会容忍你某家公司每天出一次事故,所以对Robotaxi来说你的安全性必须远高于人类,才能被社会所接受——但如果你只有10台无人的Robotaxi,你甚至安全性比人类差一些也无所谓。于是,无论马斯克怎么吹自己卖出去的几百万台车,可以在“某一天”在全球任何地方都变成L4,但他真的落地Robotaxi,也还是只敢在某个不繁忙、开车规矩的美国城市、限定区域、限制车队规模。马斯克一点也不傻,统计学学的很好,但信马斯克的人就不一定了。
也就是说,自动驾驶(L4),最核心的指标,是在满足Robotaxi用户需求的场景(包括了时段、地段的要求,比如不能不跑晚高峰,不能不去复杂区域等等)下的安全性,其次是舒适性、通行效率。这里所有的观测量包括了很多:运行时段;运行区域;事故率;舒适度;通行效率。这里其他变量,要么是一眼能看出来,要么是坐1次或者坐几次就能看出来的,只有“事故率”是个不能身边统计学的低概率事件。但因为事故率每个厂商自己心里是门清的,他会体现在其他变量上——能不能无安全员;能不能随便打车;能不能晚高峰去繁忙区域;能不能有大规模的无人车队在路上跑。大家会根据自己知道的事故率和风险,去砍量、砍形态、砍区域、砍时间,甚至砍的只剩下PPT,说自己跟别人没有代差。
所以先不考虑未来(实在是这玩意有宗教属性,不可证伪),只看当前的“考试成绩”,L4、无人驾驶、Robotaxi的核心的考题就是两个——无人和规模化。能无人的,技术上一定远好于不能的;在无人的前提下,有一定规模(起码上百)的技术上一定比无规模的好、敢随便打车的一定比只敢接“VIP”demo的好、高峰期随便打车的一定比高峰期不敢跑的好。
用直观的图来说,就是这个样子的:
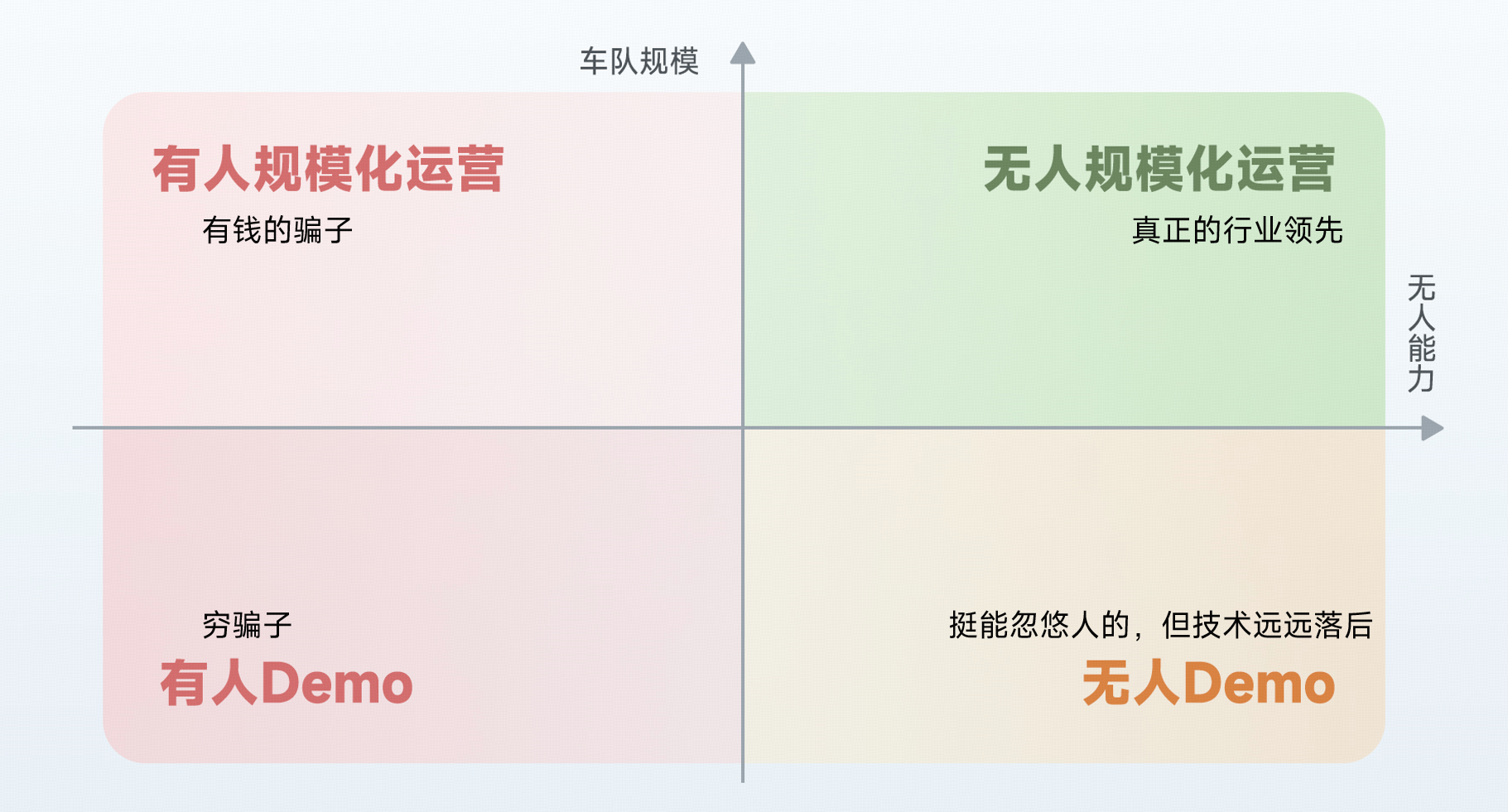
无人能力还隐含了前面提到的场景复杂度、舒适性、通行效率等等,但是这个维度更高我怕大家接受不了,就先降低下维度,相信从评价当前技术能力的角度,聪明人已经能排除掉一大堆错误选项了。
(四)落后就要挨打
领先的不会永远领先,落后的也不会永远落后,投资不止要看当前(虽然如前面所说,当前大家也看不出来),还要看未来。所以,领先的要看有没有护城河,落后的要看有没有能力追。没能力追还落后的,当然就不用看了……
护城河的话题我会在未来文章写,等写清楚Robotaxi行业领先的公司护城河都有什么,自然就大概知道什么公司才真的有可能追上。这里先简单说说什么样的是一定没有能力追的。
首先,没钱一定没能力追。但是呢,有钱不一定有能力,否则中国足球肯定不是这个名次……
其次,招不到/留不住聪明人的一定没能力追,因为自动驾驶就是很难,不聪明的人搞搞L2还行,但搞L4一定不行。这个其实大模型也是类似,DeepSeek已经证明了,清华北大、竞赛金牌,就是更厉害,本科学校、和怎么上的这个本科(是高考压线还是金牌保送还是省市级状元),比什么博士、多年AI经验,重要的多……不过呢,随着互联网和科技行业越来越难“财务自由”,现在的最年轻的那些聪明人,搞量化的比例越来越高了,对科技行业的“普通人”来说是好事,没聪明人碾压你了,但是对于公众和社会来说,肯定不是好事,因为科技进步会稍微慢一点。
中国有一批人的思维一直是“技术不重要”,“技术好的公司没用,得看别的能力”,但起码大模型和自动驾驶,都因为是“奥赛”级别的考题,导致起码截止目前,技术依然是最重要的。这是好事还是坏事,对于不同人当然是不同的了。等行业头部最聪明的人,真的把技术做到了需要有的高度,那确实可能是到了看其他非技术护城河的地步,但起码目前看,可能小几年内,自动驾驶和大模型,技术能力、通过技术研发让自身快速迭代的能力,暂时依然是最重要的。