毕业后第二次换工作,决定去小米。现在入职已经两个月了,而博客荒废了仨月。感觉也应该写点东西了。
如之前在提离职的时候写的那篇说的,我希望能找到一家能让我在某一个到几个领域成为资深码农的公司。于是选择的时候就非常简单,就是有技术并且有业务的比较大的公司。技术层面,既要有技术积累,也要有高水平的同事;业务层面,要让业务对基础架构有足够的挑战性。其实这年头满足后者的公司比前者多得多,毕竟对大多数互联网公司所做的事情来说,技术都不是决定性的,糙快猛应付下或者直接买服务在很多时候都是可行甚至反而是最佳的,提前对技术做过于超前的储备大概率会浪费(因为互联网创业大概率会死)。反过来,假设一个公司有技术积累又有高水平员工,一旦业务上不去高水平员工肯定会跑只剩下当年比较不错的技术,长期来看技术早晚要落后(前前东家就是如此)。这些原因导致业界很多公司是业务发展非常快技术可能跟不上,去这样的公司也一样有挑战但做的工作未必系统,而且同事的能力也不见得有保障。于是实际上我面的公司不多,最终拒了剩余几家,接了小米的offer。
上大学的时候用过一个摩托的手机,当时MIUI应该搞得不久,但已经有一定的口碑,加上国行自带的rom或者CM都各种难用,于是刷了MIUI,当时的感觉MIUI真是领先其他安卓ROM几个身位。所以我小米的账号id是117xxx,比很多小米老员工还靠前。后来换了iPhone5s,也就没再用过MIUI了。除此之外其实我也没咋买过小米的东西,入职前只用过充电宝和盒子。当然,早知道我要离职并且去小米,我应该就不会买T2了……总之,其实从用户的角度讲,和小米交集不大。真正从码农的角度对小米感兴趣是在我接触数据库之后了解HBase相关的东西,因为小米在HBase社区的地位而真正地关注小米。
目前我在小米也在做HBase相关的事情,当然我们不止在做HBase。单存储组就有二十来人,除了HBase/HDFS之外,还有基于HBase开发的更上层的基础服务,或解决HBase痛点问题而重新设计的C++写的新数据库,未来可能会涉猎深度学习的系统之类的。所以欢迎感兴趣的投简历。虽然每天工作的时间比在豌豆荚略长,但因为之前也要等下班比较晚的老婆一起回家所以其实在公司的时间没多多少,反而因为周末能双休觉得更轻松。我以后除非是自己当老板压榨手下员工,否则是肯定不会去一个周末上班的公司了……
对于一个互联网公司,在数据库(尤其是分布式数据库)这块,选择无非这么几种:
1,直接用云服务不招infra码农。比较适合如今新创立的小公司。
2,直接用开源的release版本。信不过云服务或信不过云服务提供的数据库或者业务够大必须自建机房的公司。
3,有自己的分支定制同时提交patch到社区防止分歧太大。公司业务比较大才有定制需求,需要能力比较强的员工。
4,定制的分支不往社区合或者走太远没法合。前一种步子大了就变成这种。
5,完全不用开源的自己造轮子。大多数巨头以及自认为是巨头的公司的搞法(当然大公司不同部门可能自行选择,有些部门造轮子有些部门用开源)。
这里面,单纯对开源数据库来说,主要是234三种模式。小米属于第三种;FB之前是第四种,据说换个老大后,直接把自己那个合不回去的分支扔了,变成第三种。当然严格来说小米自己的分支也不能“git merge”到社区,但在一些重要的功能上,会比较及时的给社区单独提patch,同时社区的新功能/bugfix也会及时的port到自己的分支,这样在功能和接口上两边差的不远,比较方便互相兼容以及升级大版本(从一个新的大版本开个新的私有分支)。感觉这是大公司最靠谱的方式,直接用社区分支,哪怕有开发人员定制往社区提交,要和社区扯皮(哪怕只是review代码也要有时差等各种蛋疼问题降低效率),失去了主动权。同时,自己开发的功能一定要往社区提交。首先,社区上的committer相当于免费为你的设计和代码review,会保证你自己开发的分支的质量。其次,提交到社区的功能,以后社区其他人开发其他东西也就必须支持这个功能,比如小米开发的反向scan提交到社区之后现在社区开发所有scan相关的功能都要考虑reverse的情况,如果不往社区提交,以后小米想把scan相关的patch移植到自己的分支就很麻烦。最后,为社区提交代码也会提高公司在社区的影响力,最直接的体现是有多个committer,在社区内掌握一定的话语权,方便提交新的功能或者保证社区的方向比较符合公司的需求。同时对社区的影响力也就是对圈内技术人的影响力,是一种很好的推广,让码农愿意加入,也容易在技术驱动的产品上形成好的口碑。
因为我比较认同小米对开源的对待方式和思路,也提高了我加入小米的意愿,正确的思路本身也是对码农的一种吸引,方便招人。至于选择做HBase,是因为觉得有事可做。在此也觉得有必要说说我对目前分布式数据库这块的想法。
目前开源的分布式数据库主要是HBase和Cassandra两大apache项目。其实对用户来说,理论上这两者只在一个事情上有差别,那就是CP和AP,用户根据需求选择即可。至于什么有没有中心节点等价值观问题,我觉得用户从业务的角度是不会在乎的。即使考虑运维成本等因素,优先级也是在对一致性和可用性的取舍之后的。但是,数据库简单说是个存数据的服务,实际上围绕最底层的引擎还有非常多的功能可以优化。我觉得Cassandra在这块明显比HBase做的好。
Cassandra理论上也是rowkey-columnkey-value的二级嵌套map,和HBase是基本一样的,区别只是一致性哈希导致rowkey尽量用哈希分布因而不是有序的。但Cassandra的数据更结构化,后来又搞了更加结构化的伪SQL,既方便入门(因为几乎所有后端码农都知道SQL),也让用户享受schema带来的各种好处。HBase目前还没看到schema化的影子,依然是半schema的,SQL相关的都是基于HBase并独立的第三方服务(小米自己也搞了一个,主要是生态链公司在用)。这样又加大了HBase本来就比较麻烦的维护工作。而且Cassandra随着逐渐加强CQL弱化老的数据模型和对应的thrift接口,在设计协议、底层引擎和文件时对schema做优化越来越深入,而HBase上层搞SQL损失的性能应该会大一些。
Cassandra“堆功能”也一直比HBase快,比如支持JSON、局部/全局二级索引等一些用户可能会非常喜欢的功能。同时在技术层引入一些东西也更快,比如offheap的MemTable,row cache(HBase只有block cache)。感觉和Datastax主导Cassandra使其社区效率更高有一定关系,同时Datastax把握用户需求的能力也更强。对于一个数据库来说,功能强大自然有更多的人用,而对于一个公司来说,在没有一个服务能满足各种需求的情况下可能会自行组合不同的技术,这就导致对其中最底层的数据库并没有那么多功能上的要求。因而虽然给HBase贡献代码的有很多的技术出众的公司,但对于很多功能那些公司(包括小米)都会额外做一些服务来满足完整的需求。这些服务不见得会开源或者大家都更倾向于对业务做更细的定制导致就算开源了也不如自己搞(反正最麻烦的事情HBase做了上层的事情简单很多)。而对于没能力自行开发的小公司来说他们可能就更倾向于直接用Cassandra这种对用户更友好的数据库了,对做业务的后端码农的要求也稍微低一些。
所以,目前从全球来看Cassandra更火一些,也是有原因的,而且也确实很多业务对强一致的需求并没有那么大(个别需要强一致的需求可能MySQL也够用)。也因为前几年Cassandra加了太多功能,导致目前其实已经没啥重要功能可加,反而导致在feature上逐渐走到瓶颈,同时因为精力放在加feature上,有时候可能导致稳定性等问题没有得到重视。HBase因为支持的feature太少,反而显得有非常多的事情可以做,比较适合深入研究、参与。而且从技术含量、复杂度等角度讲,HBase也更适合深入研究(就单说Cassandra时间戳谁大谁赢的“NTP一致性”就省了太多事情了)。并且HBase的上限也要高于Cassandra,因为CP的系统可以尽可能提高可用性,而AP的系统不可能保证100%可用并且永远实现不了强一致。而且Cassandra的原理导致两个比较大的问题是比较难解决的,一个是三备份QUORUM读写的话,一旦集群挂俩节点就悲剧,而HDFS的三备份挂俩节点还能服务。在集群机器数很多的时候,同时挂俩机器的概率会显著提高。并且他的QUORUM并不会保证顺序,因此某个请求没有发到某个节点的话理论上会永远少一份(这个时候马上新增个节点理论上是可能读不到数据的,因为只剩下一备份了),需要定期的执行repair,相当于除了compaction之外又一个增加负载的后台逻辑。另一个是一致性哈希导致新增节点前要先导完整的数据,这样当服务压力太大感觉扛不住的时候再加机器就晚了,而且导数据会增加负载反而促进系统更加扛不住,而HBase可以加一个空节点慢慢的迁移数据和region。
最近一段时间在看社区1.0和之后的版本新加进来的一些功能,比较实用但看上去不是很稳定,很可能是因为没多少用户去用所以没人踩坑。经常是边看代码边往我们自己分支的移植过程中就发现不对劲的地方,写个单元测试发现果然挂了。给社区提交patch的时候也觉得社区效率比较低,现在HBase已经有50个committer,但其实活跃的不多,目测也就十几个,会review别人的patch的就更少,加上时差,可能一些不太大的fix就能来来回回折腾一周,大一点的复杂点的就不知道要拖多久了……相对应的,比如Google的TensorFlow在论文上就有40个名字,开源后愿意贡献代码的就更多。很多时候开源项目的“热门度”会决定这个项目进步的速度,尤其是当一个项目在技术上可以碾压业界的时候,会使其成为业界标准,然后整个业界一同改良。在这点HBase/Cassandra从一开始就不是这样(不是因为初期有更好的,而是初期大家都很烂,而非最近几年的新项目很多是初期成熟度就不低),以后也更不会是这样。不过数据库天生就是一个适合稳定不适合不断升级新版的东西,所以节奏慢倒也不会让用户受不了。
如果去看HBase的commit频率,会发现其实从14年中开始HBase的开发节奏是比之前快的:
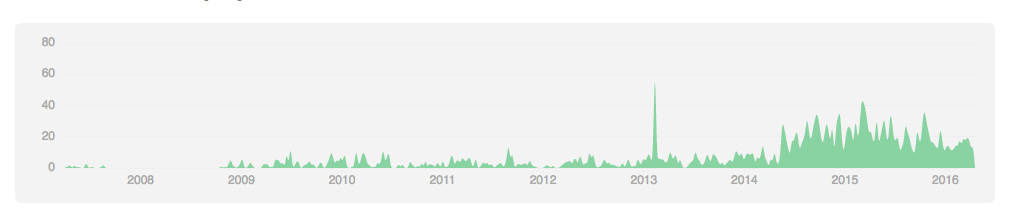
相对来说,Cassandra的commit频率比较平稳,并且commit总次数几乎是HBase的二倍:
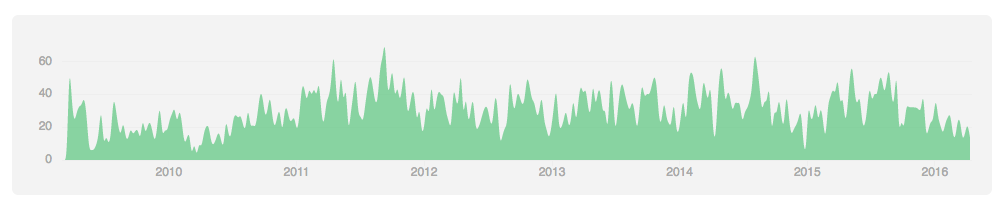
所以感觉HBase在未来还是有非常大的发展潜力,至少相比于Cassandra是这样的。而且考虑到国内实际上还是用HBase的更多,技术交流/招人也更方便,因此如果在这两者之间纠结的话,个人觉得HBase是更好的选择,0.98应该还是比较靠谱的,而且0.98和1.x也是比较兼容的,升级不是特别麻烦。小米现在涉及到0.94到0.98升级的问题,就非常蛋疼……
前面提到,HBase的上限在我看来是比Cassandra高的,而他的上限,目前看来感觉说到底就是一个问题——Java。GC的存在导致即使系统压力不大的时候也无法保证响应时间一定低于一个值,并且因此导致很多心跳相关的配置无法设的过于敏感从而导致真的挂了之后也需要等不太短的时间才敢确定这个机器挂了从而进入failover流程。并且这些年Java的开发相对来说比较缓慢,HotSpot进步实在有限,而定制JVM比定制数据库要难得多,在GC实现没有进步之前去调参来优化GC终究有点隔靴搔痒。所以目前来看如果想做新的数据库,最好还是直接用C++写,Rust也许也可以,总之不能用有GC的语言,除非其STW的时间可以控制的非常好。而最近一些新的数据库比如Kudu也都是在用C++写,包括小米现在也在做一个C++写的KV数据库。
总之未来一段时间,我会在小米做HBase相关的事情。已经是第三次签期权协议了,第一次是快跑路了公司才发期权,第二次是入职不到一年就离职了,所以至今手中没有任何已经到手的期权……小米现在的期权要求干满两年开始给,所以争取这次能真正拿到手……
发表回复